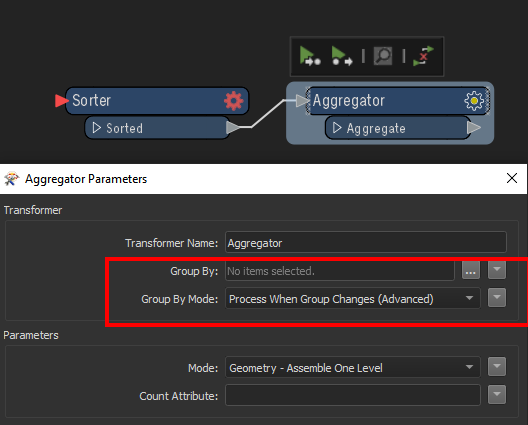
I have a dataset with 29m polygons some of which have the same attribute (say Key ID). I need to aggregate them by the Key ID but the dataset is not ordered.
After nearly 12 hours of run time it has only aggregated 1.1m features.
I need to find a better way of aggregating. Any ideas?
The data is being read from about 10 shapefiles as the source data.
I have access to Postgis if that would help.