

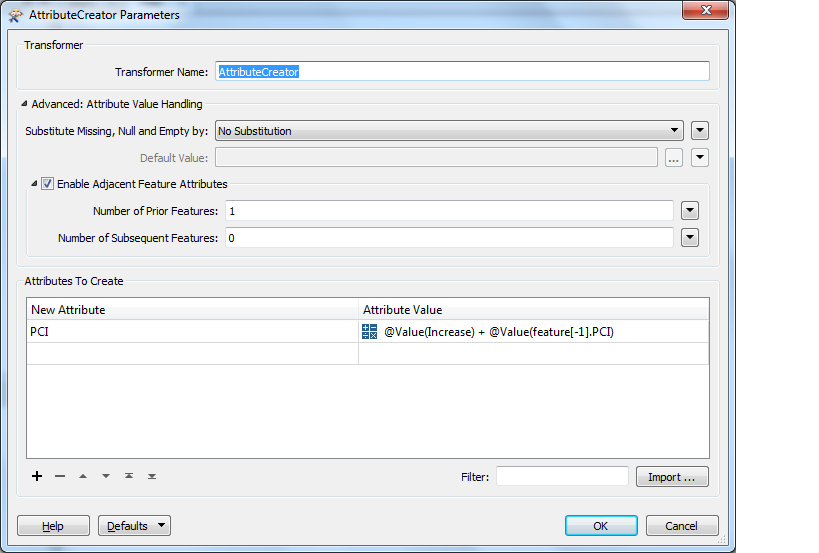
I have to put through a translation an Excel document with, say, 60 elements. I have an attribute "Action", which specifies what kind of thing happened, a second attribute, "_Increase", which is an attribute that is applied to a third attribute, "PCI" (which varies based on year - year is, incidentally, another attribute used to keep track of when a specific action takes place), depending on the type of action and when the action happened. Let's say, for the first three years (in the first three rows), "Action" is "Do Nothing" and "_Increase" = 0, I send those features directly into the writer. In year 4, an action occurs, I apply "_Increase" to Year 4's "PCI" and every subsequent year's PCI value until I reach the end of the document. Any remaining rows after that need to be filtered to the writer until the next action occurs after any applicable calculations have been applied.
Is there a transformer that can be used to automate this process? Alternatively, is there a python script (e.g. using the "Python Caller" transformer) that can be used to carry out this process?





")